kafka生产者的缓存机制
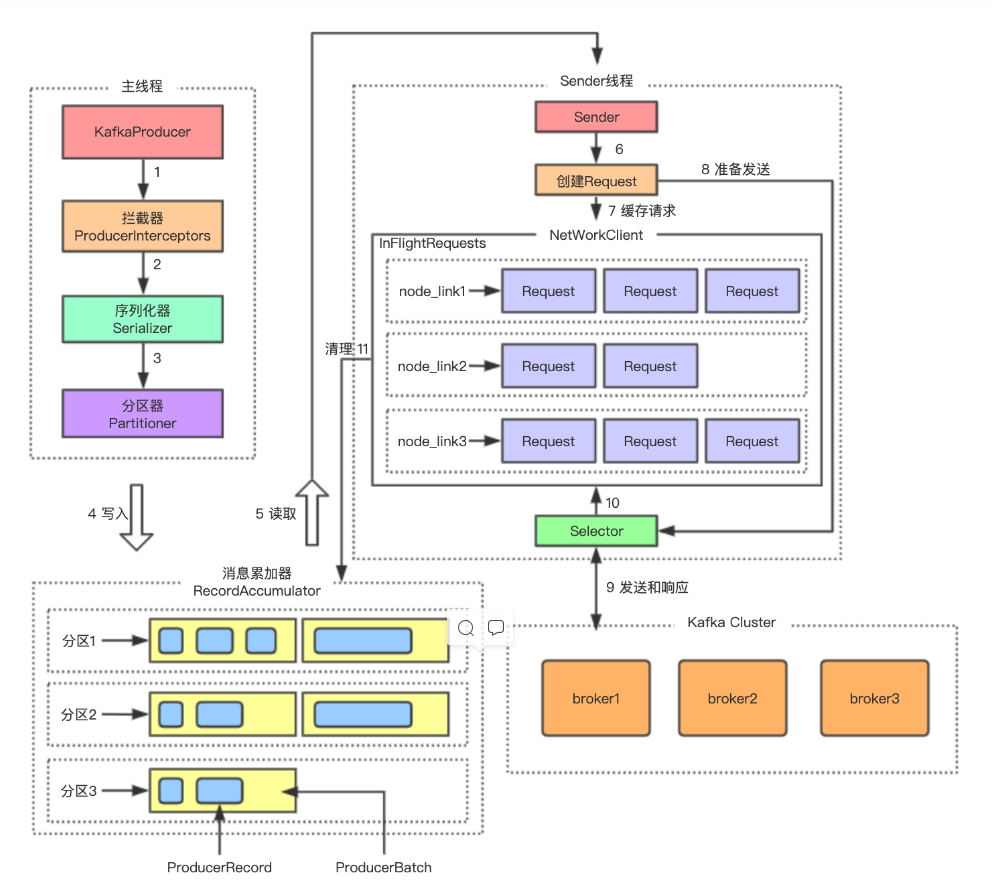
kafka生产者客户端缓存架构的设计是怎样的?我们先整体看下发送消息到java资料分服务端的完整过程和架构:
消息累加器
其实,整个生产者客户端是由两个线程协调运行的,一个是主线程Producer线程,一个是Sender线程。由主线程生产消息,然后缓存到消息累加器(RecordAccumulator);而Sender线程则负责从消息累加器中不断获取消息,然后发送到kakfa broker。这个过程大致如下图:
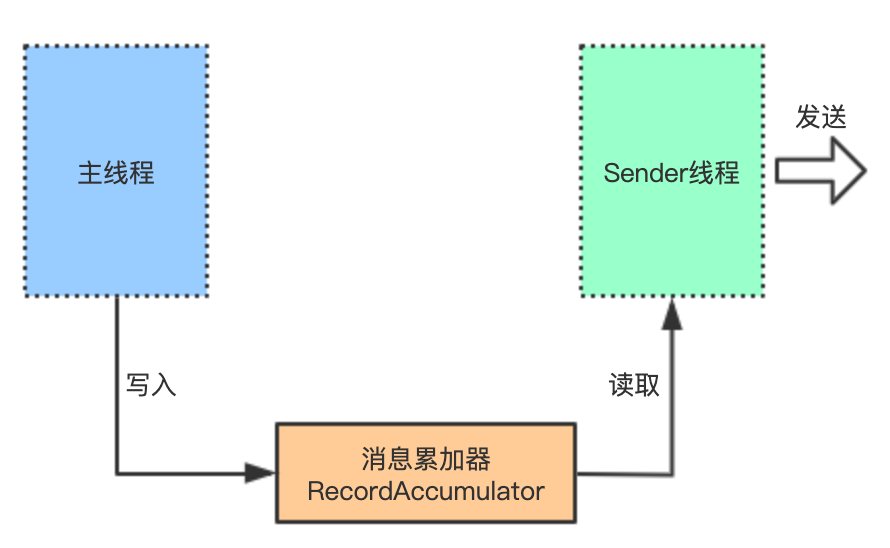
那为什么需要消息累加器呢?直接发送不是更直接?其实主要是用来缓存消息以便Sender线程可以每次批量发送,从而减少网络传输的资源消耗;而数据到服务端,服务端也可以批量写操作,从而减少磁盘I/O资源消耗,可以提升性能。这个设计,也可以运用于我们平时的业务需求场景开发中。
那幺消息累加器中的结构是怎样的呢?消息累加器的内部为每个区分维护一个双端队列Deque,队列的内容是ProducerBatch;而ProducerBatch包含了一个或者多个ProducerRecord消息。
ConcurrentMap> batches;
具体结构如下图:
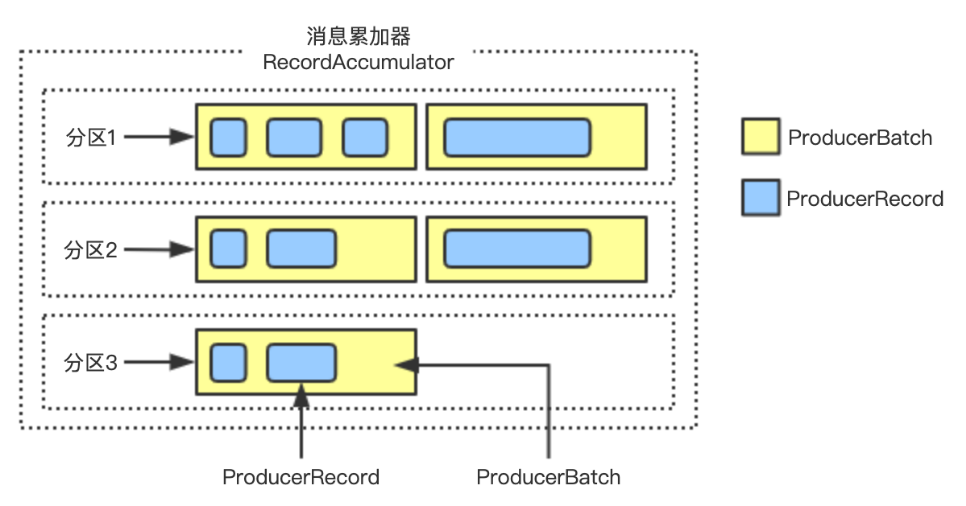
消息Record写入到消息累加器时,会被追加到双端队列的尾部。而尾部的ProducerBatch剩余可用空间也意味着能否再写入本次的这条消息ProducerRecord。ProducerBatch的大小和batch.size参数有着密切的关系。batch.size的参数大小控制着ProducerBatch的大小,默认是16KB大小。

整个过程是这样的:
消息写入到消息累加器时,先寻找其对应分区的双端队列(如果不存在则新建队列)
从双端队列的尾部获取一个ProducerBatch对象(如果不存在则新建Batch对象)
判断ProducerBatch是否还有剩余空间写入本次的消息Record,如果可以则写入(如果不可以则需要创建一个新的ProducerBatch对象)
新建ProducerBatch对象时会评估这条消息的大小是否超过batch.size参数的大小,如果不超过则以batch.size参数大小创建Batch对象(如果超过,就以消息的评估大小创建新Batch对象)。而用batch.size创建的内存空间是会被BufferPool管理的,可以进行空间复用;而超过batch.size创建的内存空间则不会被复用,使用完成则被回收。
而整个消息累加器的缓存空间与buffer.memory参数有关。默认是32MB大小。如果生产者客户端需要向很多区分发送比较多的消息,则可以根据实际情况将此参数适当调大以增加整体的吞吐量。

Sender线程
Sender线程则异步从消息累加器中获取缓存的消息,然后将其转为指定格式的ProducerRequest对象,将Request对象请求发往各个broker了。不过,请求在从Sender线程发往broker之前还会被保存到InFlightRequests中,其主要作用是缓存了已经发出去但还没有收到服务端响应的请求。
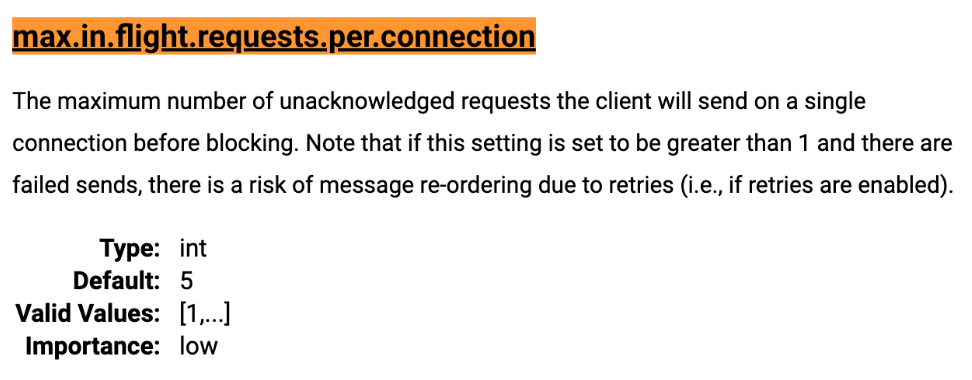
InFlightRequests相关的有一种重要的配置参数是
max.in.flight.requests.per.connection。该参数表示每个连接(客户端与broker node节点之间的网络连接)的最多缓存请求数,默认值为5个。当超过该数值之后,消费者客户端便不能再向这个连接发送更多的请求了。另外也得注意,当该参数配置大于1时,由于因为失败重试原因,可能会存在消息乱序的风险。
总结
本次我们了解了生产者客户端的两个线程,主线程Producer线程和Sender线程的各自的职责和作用;同时也了解了kafka的Producer客户端发送缓存机制。对于优秀的设计机制,我们也可以思考借鉴运用于其他类似的业务开发中。


 微信收款码
微信收款码 支付宝收款码
支付宝收款码