Redis数据类型应用场景
Redis数据类型应用场景
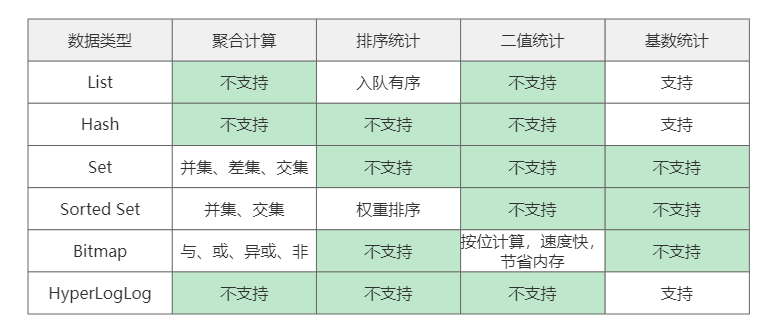
在Redis中常用类型为五个String、List、Hash、Set、Sorted Set,扩展类型为三个GEO、BitMaps、HyperLogLog,那我们对这些类型的特性是否了解呢,什幺业务场景下选择什幺样的数据类型呢,下面借助多种常见业务场景聊聊数据类型的选择。
聚合计算
聚合计算就是指多个集合间的聚合结果如
交集:统计多个集合间的相同元素。
并集:统计多个集合间的所有元素,相同元素只显示一个。
差集:两个集合对比,统计一个集合对于另外一个集合独有的元素。
有聚合计算功能为Set、Sorted Set两个,但需要注意的是Sorted Set集合没有差集计算功能。
Set聚合运算命令如下
127.0.0.1:6379> SADD test1 1 2 3 4 5 6 7
(integer) 7
127.0.0.1:6379> SADD test2 3 5 2 9 10
(integer) 5
## 并集计算 如果想将结果存入单独的集合中可以使用SUNIONSTORE
## SUNION时间复杂度O(N) SUNIONSTORE时间复杂度O(N)
127.0.0.1:6379> SUNION test1 test2
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "9"
9) "10"
## 差集计算 如果想将结果存入单独的集合中可以使用SDIFFSTORE
## SDIFF时间复杂度O(N) SDIFFSTORE时间复杂度O(N)
127.0.0.1:6379> SDIFF test1 test2
1) "1"
2) "4"
3) "6"
4) "7"
## 交集计算 如果想将结果存入单独的集合中可以使用SINTERSTORE
## SINTER 时间复杂度O(N*M) N 为给定集合当中基数最小的集合, M 为给定集合的个数
## SINTERSTORE 时间复杂度O(N*M)
127.0.0.1:6379> SINTER test1 test2
1) "2"
2) "3"
3) "5"
Sorted Set聚合命令如下
127.0.0.1:6379> ZADD test1 100 a 99 b 89 c 97 d 101 e
(integer) 5
127.0.0.1:6379> zadd test2 110 a 100 b 90 k 99 f
(integer) 4
######################################计算合集##########################
## numkeys指参与计算key的数量,AGGREGATE统计方式默认是SUM WEIGHTS指给每个集合元素的score乘上weight(乘法因子)
## ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
## 时间复杂度O(N)+O(Mlog(M)), N为给定有序集基数的总和, M为结果集的基数。
127.0.0.1:6379> ZUNIONSTORE test3 5 test1 test2 weights 1 1
(integer) 7
127.0.0.1:6379> ZRANGE test3 0 -1 withscores
1) "c"
2) "89"
3) "k"
4) "90"
5) "d"
6) "97"
7) "f"
8) "99"
9) "e"
10) "101"
11) "b"
12) "199"
13) "a"
14) "210"
######################################计算并集##########################
## ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
## 时间复杂度O(N*K)+O(Mlog(M)), N为给定key中基数最小的有序集, K为给定有序集的数量, M为结果集的基数。
127.0.0.1:6379> ZINTERSTORE test3 2 test1 test2 weights 1 1 aggregate max
(integer) 2
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> ZRANGE test3 0 -1
1) "b"
2) "a"
127.0.0.1:6379> ZRANGE test3 0 -1 withscores
1) "b"
2) "100"
3) "a"
4) "110"
不论是Set还是Sorted Set在聚合运算时的时间复杂度都是较高的,对于大数据的运算就会阻塞主线程。
如果Redis采用的是主从模式建议采用从库计算,但从库计算一定需要注意的是从库不允许写只允许读所以对于SUNIONSTORE、SDIFFSTORE、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE这类需要写入目标集合的命令显然是不可行的,需要根据业务进行取舍。
如果采用的是Cluster集群模式,去执行聚合统计那幺可能发生错误,因为聚合包含的key可能不在同一个实例中导致报错,演示如下。
在Cluster集群中存在主节点7002、7003、7004详细信息如下所示。

### 在集群7004中新增set集合key为test
127.0.0.1:7004> SADD test 1 2 3 4 5 6 7 8 0 10 5 15 12 13
(integer) 13
### 在集群7003中新增set集合key为test1
127.0.0.1:7003> SADD test1 11 4515 12 13
(integer) 4
### 在集群7003中执行聚合命令,报错!!!!!!!
127.0.0.1:7003> SUNION test1 test
(error) CROSSSLOT Keys in request don't hash to the same slot
所以建议把这些统计数据与在线业务数据拆分开,实例单独部署,防止在做统计操作时影响到在线业务。
排序统计
对于排序有很多业务场景如小说热榜、排行榜等,在Redis中具排序功能的是Sorted Set和List,需要注意的是List没有排序命令而是根据写入顺序排序,而Sorted Set则可以通过权重进行排序。
List命令演示如下,如果元素是按顺序入队那幺统计没有问题,但如果是中间插入数据需要人为判断过于复杂,在排序统计中不建议使用。
127.0.0.1:6379> lpush test 1 2 3 4 5 6 7
(integer) 7
127.0.0.1:6379> LRANGE test 0 -1
1) "7"
2) "6"
3) "5"
4) "4"
5) "3"
6) "2"
7) "1"
127.0.0.1:6379> rpush test 0
(integer) 8
127.0.0.1:6379> LRANGE test 0 -1
1) "7"
2) "6"
3) "5"
4) "4"
5) "3"
6) "2"
7) "1"
8) "0"
127.0.0.1:6379> lpush test -1
(integer) 9
127.0.0.1:6379>
127.0.0.1:6379> LRANGE test 0 -1
1) "-1"
2) "7"
3) "6"
4) "5"
5) "4"
6) "3"
7) "2"
8) "1"
9) "0"
Sorted Set命令演示如下,Sorted Set无论以怎样的方式插入集合都会根据权重进行排序,非常适用于各种排序统计逻辑。
127.0.0.1:6379> ZADD test 100 a 80 b 99 c 109 d 40 f 77 h
(integer) 6
127.0.0.1:6379> ZRANGEBYSCORE test -inf +inf withscores
1) "f"
2) "40"
3) "h"
4) "77"
5) "b"
6) "80"
7) "c"
8) "99"
9) "a"
10) "100"
11) "d"
12) "109"
127.0.0.1:6379> ZADD test 78 q
(integer) 1
127.0.0.1:6379>
### ZRANGE和ZRANGEBYSCORE的不同点在于ZRANGE是根据下标范围查询列表
### ZRANGEBYSCORE根据scores范围查询列表
127.0.0.1:6379> ZRANGE test 0 -1
1) "f"
2) "h"
3) "q"
4) "b"
5) "c"
6) "a"
7) "d"
127.0.0.1:6379> ZRANGE test 0 -1 withscores
1) "f"
2) "40"
3) "h"
4) "77"
5) "q"
6) "78"
7) "b"
8) "80"
9) "c"
10) "99"
11) "a"
12) "100"
13) "d"
14) "109"
二值状态统计
二值指的是值只有两种状态,最典型的例子就是签到统计,统计是否签到只需要两种状态是和否,只要涉及到两种状态的都可以采用如下的形式。
二值统计可以使用Bitmap来做统计,Bitmap其底层就是String,String类型会被保存为一个字符数组buf[],而Bitmap就是利用这一特性将数组的每一个bit位利用起来,用来表示一个元素的二值状态,所以可以将Bitmap理解为是一个字符数组构成的。
如需要统计用户id为10001的4月打卡情况可以如下模拟
### 因为Bitmap的offset从0开始,所以在统计的时候从0开始计算
127.0.0.1:6379> SETBIT sign:user:10001:202204 0 1
(integer) 0
127.0.0.1:6379> SETBIT sign:user:10001:202204 1 1
(integer) 0
127.0.0.1:6379> SETBIT sign:user:1000:2022041 2 1
(integer) 0
127.0.0.1:6379> SETBIT sign:user:10001:202204 4 1
(integer) 0
127.0.0.1:6379> SETBIT sign:user:10001:202204 5 1
(integer) 0
### 统计bit位为1的个数,统计已签到次数
127.0.0.1:6379> BITCOUNT sign:user:10001:202204
(integer) 5
如果需要统计4月有多少个用户连续签到,这个可以利用Bitmap的按位运算的特性计算,将key按照时间划分进行统计,采用BITOP做按位运算
BITOP operation destkey key [key ...]
operation 支持四种参数
BITOP AND destkey srckey1 srckey2 srckey3 ... srckeyN ,对一个或多个 key 求逻辑并(同为1才为1、只要有0就为0),并将结果保存到 destkey 。
BITOP OR destkey srckey1 srckey2 srckey3 ... srckeyN,对一个或多个 key 求逻辑或(同为0才为0、只要有1就为1),并将结果保存到 destkey 。
BITOP XOR destkey srckey1 srckey2 srckey3 ... srckeyN,对一个或多个 key 求逻辑异或(相异为1、相同为0),并将结果保存到 destkey 。
BITOP NOT destkey srckey,对给定 key 求逻辑非,并将结果保存到 destkey 。
### 采用日期作为key,每个bit位就是一个用户,这样计算占用内存小同时效率高
127.0.0.1:6379> SETBIT 20220401 0 1
(integer) 0
127.0.0.1:6379> SETBIT 20220401 1 1
(integer) 0
127.0.0.1:6379> SETBIT 20220401 2 1
(integer) 0
127.0.0.1:6379> SETBIT 20220401 3 1
(integer) 0
127.0.0.1:6379> SETBIT 20220401 4 0
(integer) 0
127.0.0.1:6379> SETBIT 20220402 0 0
(integer) 1
127.0.0.1:6379> SETBIT 20220402 1 1
(integer) 0
127.0.0.1:6379> SETBIT 20220402 2 1
(integer) 0
127.0.0.1:6379> SETBIT 20220402 3 0
(integer) 0
127.0.0.1:6379> SETBIT 20220402 4 1
### 按位运算,每天都签到那幺对应每天的日期key上相同bit为应都为1
127.0.0.1:6379> BITOP and test 20220402 20220401
(integer) 1
127.0.0.1:6379> BITCOUNT test 0 -1
(integer) 2
127.0.0.1:6379>
基数统计
首先需要了解的是什幺为基数,基数就是不会重复的数字,对于基数统计就是统计元素中不会重复的元素,常见于网站的PV(网页点击量一个用户一天内点击多次也只算一次)、UV(独立访客数,一个用户一天内进入多次也只计算一次)统计,这个统计其实方案有很多,如Set、HyperLogLog,甚至可以使用Hash。
Set方案
Set集合本来就是可以去重的,所以在计算时只要将用户id设置到集合中即可
### 用户1001 20220401 访问page1页面
127.0.0.1:6379> SADD web:page1:20220401 1001
(integer) 1
### 用户1002 20220401 访问page1页面
127.0.0.1:6379> SADD web:page1:20220401 1002
(integer) 1
### 用户1001 20220401 访问page1页面
127.0.0.1:6379> SADD web:page1:20220401 1001
(integer) 0
### 统计pv数
127.0.0.1:6379> SCARD web:page1:20220401
(integer) 2
127.0.0.1:6379>
127.0.0.1:6379> SMEMBERS web:page1:20220401
1) "1001"
2) "1002"
### 用户1001 20220401 进入系统
127.0.0.1:6379> SADD web:user:20220401 1001
(integer) 1
### 用户1002 20220401 进入系统
127.0.0.1:6379> SADD web:user:20220401 1002
(integer) 1
### 用户1001 20220401 进入系统
127.0.0.1:6379> SADD web:user:20220401 1001
(integer) 0
### 统计uv数
127.0.0.1:6379> SCARD web:user:20220401
(integer) 2
Hash方案
Hash方案和Set方案类型,Hash方案是利用了Hash中的属性不能重复的特性来处理。
### 用户1001 20220401 访问page1页面
127.0.0.1:6379> HSET web:page1:20220401 1001 1
(integer) 1
### 用户1002 20220401 访问page1页面
127.0.0.1:6379> HSET web:page1:20220401 1002 1
(integer) 1
### 用户1001 20220401 访问page1页面
127.0.0.1:6379> HSET web:page1:20220401 1001 1
(integer) 0
### 统计pv数
127.0.0.1:6379> HLEN web:page1:20220401
(integer) 2
### uv类似
HyperLogLog方案
无论是hash方案还是set方案如果用户数据量逐渐增加,集合的内存消耗也将大幅度提升会出现bigkey的情况,再来看看HyperLogLog,redis官网这样描述:
A HyperLogLog is a probabilistic data structure used in order to count unique things (technically this is referred to estimating the cardinality of a set). Usually counting unique items requires using an amount of memory proportional to the number of items you want to count, because you need to remember the elements you have already seen in the past in order to avoid counting them multiple times. However there is a set of algorithms that trade memory for precision: you end with an estimated measure with a standard error, in the case of the Redis implementation, which is less than 1%. The magic of this algorithm is that you no longer need to use an amount of memory proportional to the number of items counted, and instead can use a constant amount of memory! 12k bytes in the worst case, or a lot less if your HyperLogLog (We’ll just call them HLL from now) has seen very few elements.
译:
HyperLogLog是一种概率数据结构,用于计算唯一的东西(从技术上讲,这指的是估计集合的基数)。通常计算唯一的条目需要使用与要计算的条目数量成比例的内存,因为您需要记住过去已经看到的元素,以避免多次计算它们。然而有一套算法可以用精度换内存,在Redis实现的情况下,你会得到一个标准误差的估计值,误差小于1%。这个算法的神奇之处在于,您不再需要使用与所计数的项目数量成比例的内存,而是可以使用恒定的内存数量!最坏情况下是12k字节,HyperLogLog(从现在开始我们就称它们为HLL)只看到的元素则会少很多。
HyperLogLog代码演示如下
127.0.0.1:6379> info memory
# Memory 初始内存容量
used_memory:927936
# Memory 第一次添加内存容量
127.0.0.1:6379> PFADD web:pv:20220424 1001 1002 1003 1004 1005 1006 1007
(integer) 1
127.0.0.1:6379> info memory
used_memory:928080
# Memory 第二次添加内存容量
127.0.0.1:6379> PFADD web:pv:20220424 10101 10102 10103 10104 10105 10106 10017
(integer) 1
127.0.0.1:6379> info memory
used_memory:928128
# Memory 第二次添加内存容量
127.0.0.1:6379> PFADD web:pv:20220424 1041201 1042102 1012403 1012404 1012405 1012406 1002317
(integer) 1
127.0.0.1:6379> info memory
used_memory:928224
# Memory 第二次添加内存容量
127.0.0.1:6379> PFADD web:pv:20220424 10415201 10425102 10152403 10512404 10125405 10124506 10052317
(integer) 1
127.0.0.1:6379> info memory
used_memory:928224
################后续持续加入基数,内存容量保持928224不变基数查询正常#############
### 基数查询
127.0.0.1:6379> PFCOUNT web:pv:20220424
(integer) 49
HyperLogLog就是概率性的结构,采取精度换空间的形式,内存消耗是固定的不会随着基数的增加内存增大,所以在业务要求数据精度不高的情况下如统计网站pv、uv这类业务完全可以使用HyperLogLog解决,但如果业务要求精度过高则还是采用Set或者Hash数据类型较为稳妥。
总结
Redis效率高的一个重要原因就是支持丰富的数据结构,正确的选择数据结构对于业务是非常重要的,将数据类型和常见业务对比总体如下。

 微信收款码
微信收款码 支付宝收款码
支付宝收款码